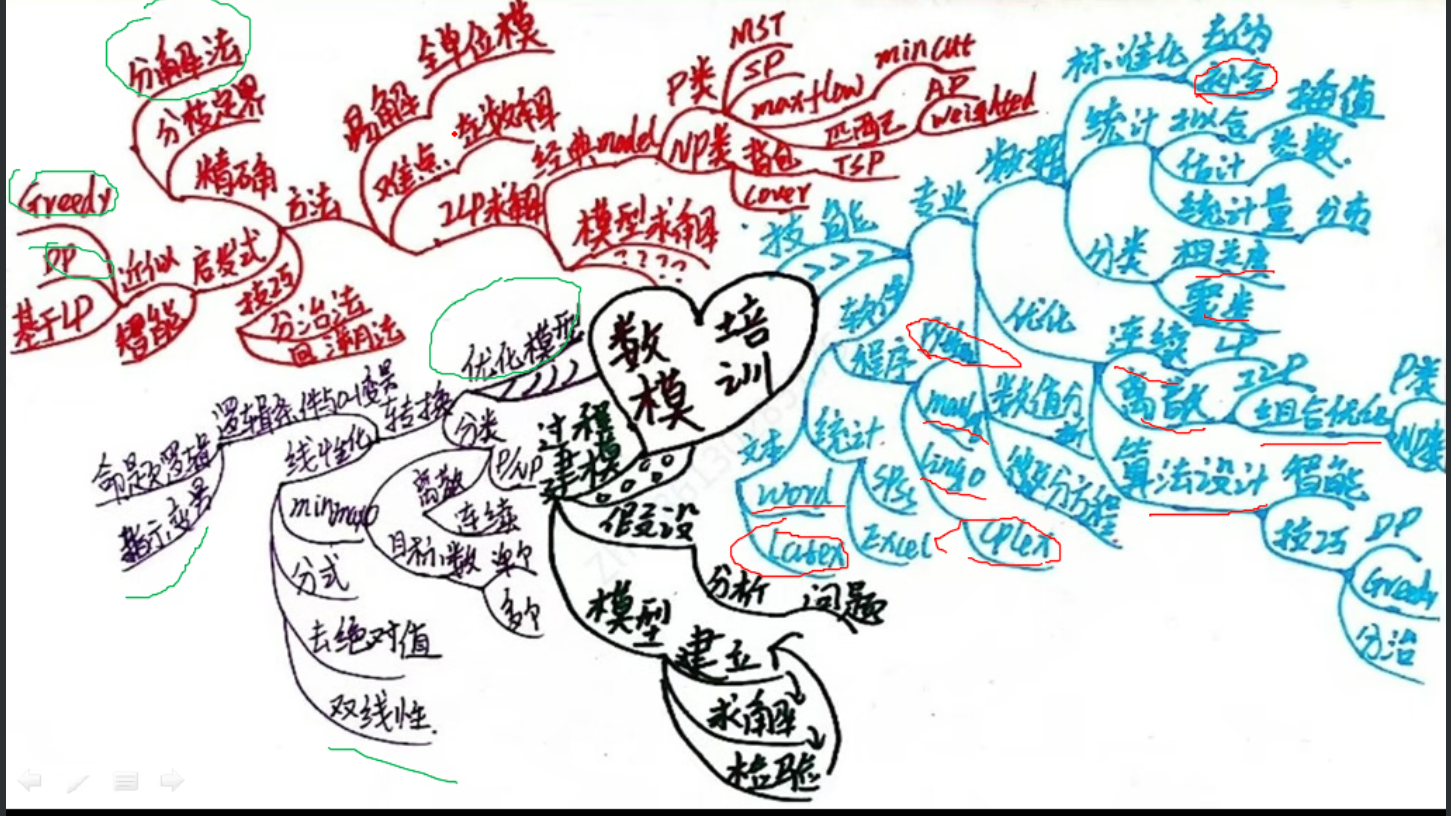
数学建模:历年优秀论文+入门+进阶+美赛(国赛待更新) - 知乎 (zhihu.com)
核心:关键是要搞清楚什么样的问题用什么样的方法,然后现学现卖。
//常用模型
规划类:线性规划、非线性规划、动态规划、多目标优化模型
模拟类:线性回归、多元线性回归、BOX-COX变换、残差分析
预测类:时间序列、灰度、logistics、SEIR、微分差分方程、马尔科夫链
权重确定类:AHP、主成分分析、因子分析法、熵权法、模糊评价法
其他常用类:图、排队论、社会力模型、决策树、博弈论
//常用方法
蒙特卡洛法、Dijkstra、Floyd、穷举法、元胞自动机
//常用学习思路
先学习模型的公式,再了解模型的使用情境、可应用的问题类型,最后将公式推
导和原理推导手动完成一遍。
//常见子问题
1.已知x1,x2,x3,...,单位盈利为w1,w2,w3,...,多个目的地与起点的距离是d1,d2,d3,...,对应的单位距离的运费为z1,z2,z3,...,试求一个盈利最大运费最小的方案。
2.已知路口的车流流入量lamdba,红绿灯n秒且忽略黄灯,在车流量稳定的情况下试分析车辆在路口的平均等待时间。
3.结合第a学期b门课程的成绩,评估某年级某院某班级的每个学生的学习能力。
4.结合历年来五一长假期间西安机场的航班情况,试预测今年五一期间机场在何时达到客流量的高峰,客流量大致为多少。
5.TSP问题。
6.试画出各种数据已知的气球在穿越n层风速为vi(i=1,2,3,...,n)的气流层时的轨迹。
7.试给出方案确定学校应该新增座椅的数量和位置,学校地形、椅子成本已知。
8.商场拟定根据历年来顾客的购买数据进行分析,调整促销商品的种类和价格,试给出方案。
9.请根据雪崩的物理原理建立模型模拟雪崩随时间的变化。
10.根据每日治愈人数、感染人数以及其他数据建立传染病模型。
一、补
插值拟合
插值与拟合是数学建模中的一种基本的数据分析手段,被公认为建模中常用的算法之一。
插值算法是在现有的数据是极少的,不足以支撑分析的进行,需要“模拟产生”一些新的但又比较靠谱的值来满足需 求,这就是插值的作用。(根据现有的数据点,构造过这些个数据点的近似函数)
什么是插值?牛顿插值的几何解释是怎么样的? - 马同学的回答 - 知乎 https://www.zhihu.com/question/22320408/answer/141973314
拟合问题的目标是寻求一个函数(曲线),使得该曲线在某种准则下与所有的数据点最为接近,即曲线拟合的最 好(最小化损失函数)。(已知有限个数据点,求近似函数,不要求过已知数据点,只要求在某种意义下它在这 些点上的总偏差最小)


曲线拟合的思想:已知一组二维数据,即平面上的 n 个点寻求一个函数(曲线)f(x),使得在某种准则下 f(x) 与所有数据点最为接近, 其中最常用的一种拟合方法就是线性最小二乘法.

(?)
MATLAB最小二乘法拟合曲线公式 - 知乎 (zhihu.com)
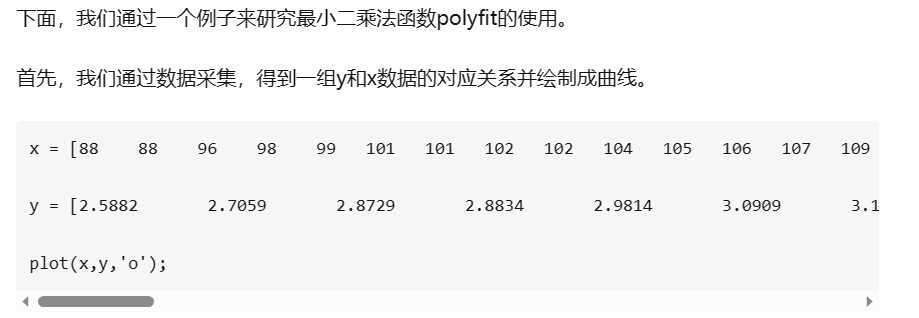
Y = P(1)*X^N + P(2)*X^(N-1) + ... + P(N)*X + P(N+1)拟合公式
在 MATLAB 中,polyfit(x, y, n) 是一个用于多项式拟合的函数。以下是对此函数的解释:
- x:表示自变量(或横轴)数据的向量或矩阵。
- y:表示因变量(或纵轴)数据的向量或矩阵。它的大小应与 x 相匹配。
- n:表示所需拟合的多项式的次数。
当调用 polyfit(x, y, n) 函数时,MATLAB 会对给定的数据点进行多项式拟合,并返回拟合多项式的系数。在你的问题中,你使用了 n=1,即一次多项式(线性拟合)。
polyfit(x, y, 1) 的返回值 coefficient 是一个包含两个元素的向量,其中第一个元素是拟合多项式的斜率(即直线的斜率),第二个元素是拟合多项式的截距(即直线的截距)。
通过使用 polyfit(x, y, 1) 进行线性拟合,你可以得到一条最佳拟合线,该线通过数据点集(x, y),使得拟合线与数据点的残差平方和最小化。
此外,polyfit 函数还可以用于高阶多项式拟合(增加 n 的值)。但请注意,在进行多项式拟合时,需要谨慎选择多项式的阶数,以避免过度拟合或欠拟合的问题。
在MATLAB中,
polyval(coefficient, x)函数用于计算通过多项式拟合的系数coefficient得到的自变量x对应的因变量yn的值。以下是对此函数的解释:
- coefficient:表示多项式拟合的系数的向量。这些系数通常是使用
polyfit函数计算得到的。- x:表示自变量的向量或矩阵。
- yn:表示通过多项式拟合计算得到的因变量的向量或矩阵。其大小与
x相匹配。当调用
polyval(coefficient, x)函数时,MATLAB会使用给定的多项式拟合系数coefficient来计算自变量x对应的因变量yn的值。这个过程涉及将x的每个值代入多项式中,并计算出相应的因变量值。使用
polyval函数可以通过拟合多项式来估计未知数据点的因变量值。这对于在给定的自变量范围内进行插值或外推是非常有用的。需要注意的是,
polyval函数只能用于已经进行多项式拟合的情况,其中coefficient是由polyfit函数计算得到的多项式系数向量。
假设我们有一组数据点,每个数据点包含了自变量 X 和因变量 Y 的取值。我们希望找到一个多项式函数,使得该函数能够很好地描述这些数据点的关系。
公式 Y = P(1)*X^N + P(2)*X^(N-1) + … + P(N)*X + P(N+1) 中的参数 P(1), P(2), …, P(N+1) 可以通过拟合的过程来确定。我们可以通过最小化拟合误差,即将每个数据点的实际值 Y 与多项式函数计算得到的值进行比较,并求得最优的参数值,使得两者之间的差异最小化。
多项式拟合是一种常见的数据拟合技术,用于找到一个多项式函数来逼近给定的一组数据点。以下是使用公式 Y = P(1)*X^N + P(2)*X^(N-1) + … + P(N)*X + P(N+1) 进行多项式拟合的详细步骤:
- 收集数据:首先,收集包含自变量 X 和因变量 Y 的一组数据点。这些数据点可以来自实验观测、实际测量或其他来源。
- 确定多项式次数:根据数据的特征和拟合需求,确定多项式的次数 N。次数越高,多项式的灵活性越大,但也可能导致过度拟合。
- 构建矩阵:构建一个 (N+1)×(N+1) 的矩阵 X 和一个 (N+1)×1 的列向量 Y。其中,矩阵 X 的第 i 行第 j 列的元素为 X_i^(N-j)(即自变量 X 的幂次方),列向量 Y 的第 i 行表示对应的因变量 Y 的取值。
- 解线性方程组:解线性方程组 X * P = Y,其中矩阵 P 是一个 (N+1)×1 的列向量,表示多项式的系数。通过求解此线性方程组,可以得到最优的多项式系数 P。
- 得到拟合函数:根据求解得到的多项式系数 P,构建拟合函数 Y_fit = P(1)*X^N + P(2)*X^(N-1) + … + P(N)*X + P(N+1)。
- 评估拟合效果:使用适当的指标(如均方误差、决定系数等)来评估拟合函数与原始数据之间的拟合效果。较小的误差和较高的决定系数表示拟合结果较好。
请注意,多项式拟合可能会受到过度拟合的问题,特别是在多项式次数较高时。因此,在进行多项式拟合时,需要谨慎选择多项式次数,并使用合适的模型评估方法进行验证。
总结一句话:到时候照着这步骤套公式即可,无需了解其原理。
二、7.6日 线性目标
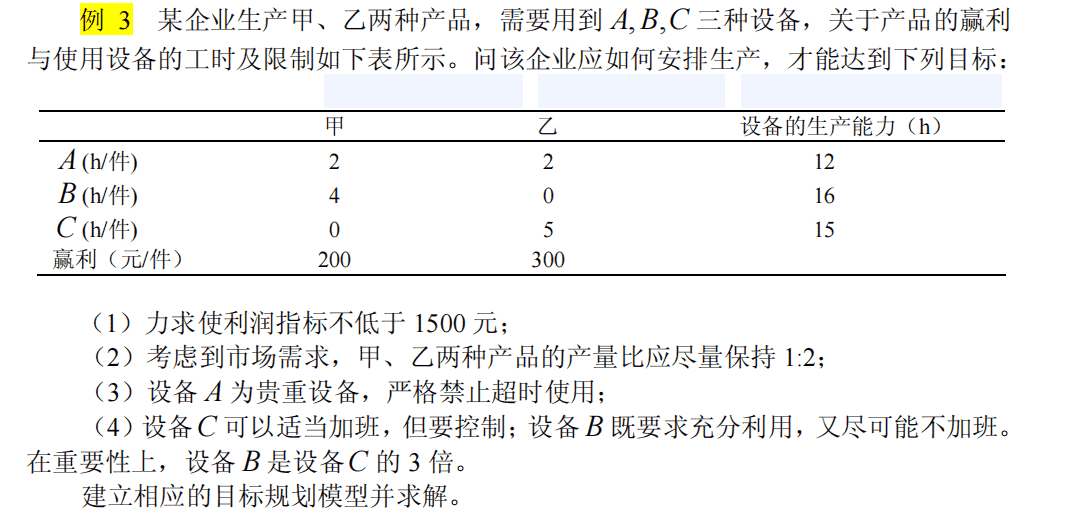
1.线性规划目标模型——生产盈利问题
eg1:
eg2:
例6 某计算机公司生产三种型号的笔记本电脑 A, B,C 。这三种笔记本电脑需要 在复杂的装配线上生产,生产1台 A, B,C 型号的笔记本电脑分别需要5,8,12(h)。公 司装配线正常的生产时间是每月1700h。公司营业部门估计 A, B,C 三种笔记本电脑的利 润分别是每台1000,1440,2520(元),而公司预测这个月生产的笔记本电脑能够全部 售出。公司经理考虑以下目标:
第一目标:充分利用正常的生产能力,避免开工不足;
第二目标:优先满足老客户的需求, A, B,C 三种型号的电脑50,50,80(台), 同时根据三种电脑的纯利润分配不同的权因子;
第三目标:限制装配线加班时间,最好不要超过200h;
第四目标:满足各种型号电脑的销售目标,A, B,C 型号分别为100,120,100(台), 再根据三种电脑的纯利润分配不同的权因子;
第五目标:装配线的加班时间尽可能少。 请列出相应的目标规划模型,并用LINGO软件求解
2.运输问题
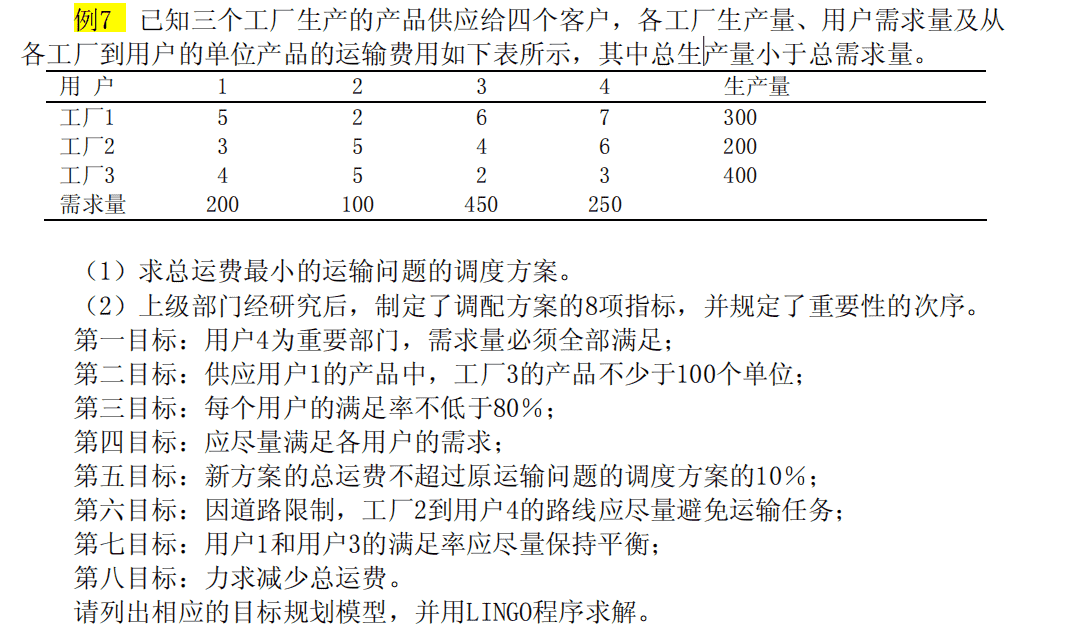
3.Lingo使用教程
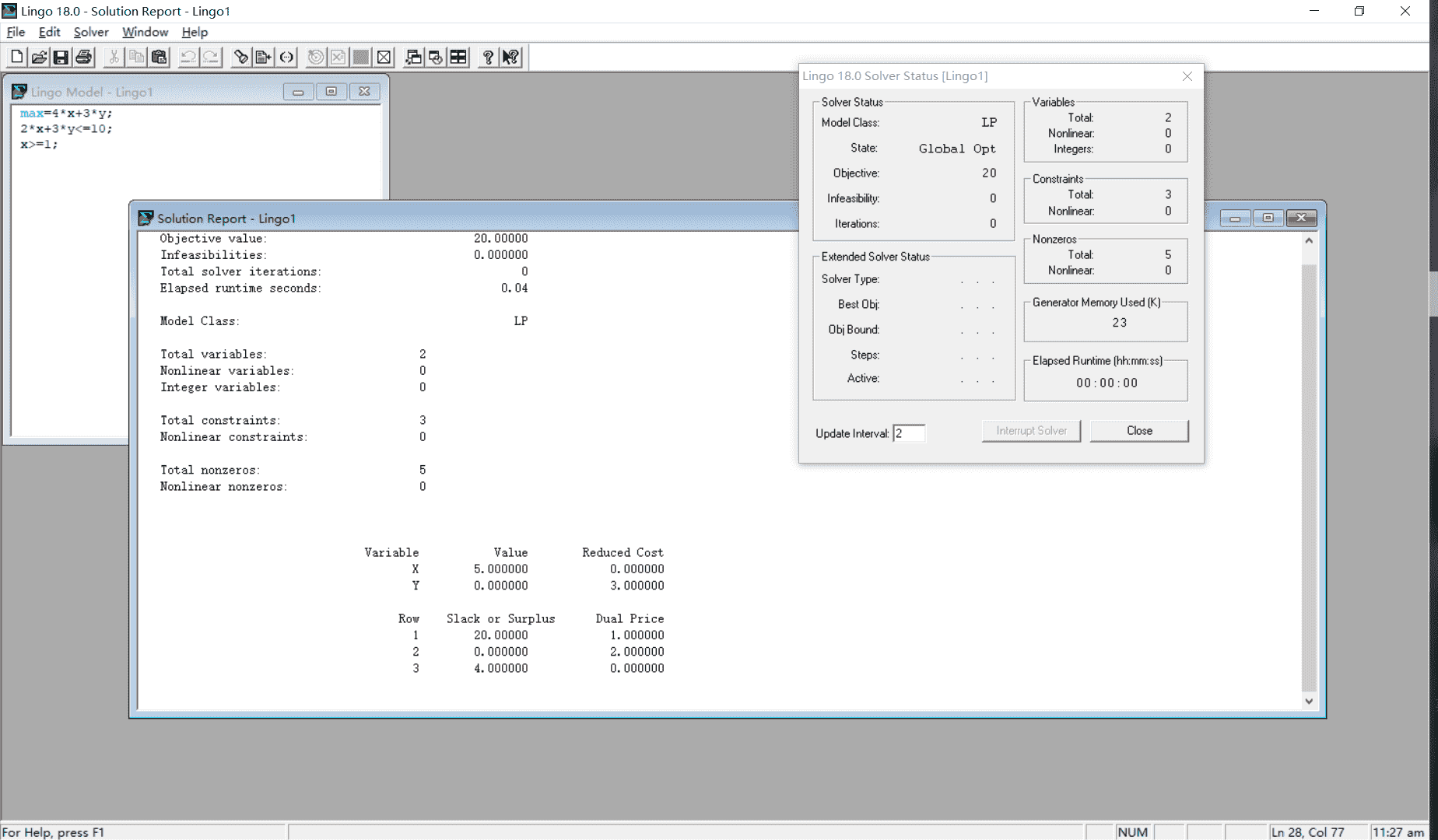
- Global optimal solution found.
表示全局最优解找到 - Objective value:
表示最优目标值 - Total solver iterations:
表示用单纯行法进行了两次迭代 - Variable
表示变量,运行结果中有两个变量为x1,x2 - Value
给出最优解中个变量的值 - Reduced Cost
与最优单纯形表中的检验数相差一个符号的数。
为了使某个变量在解中的数值增加一个单位,目标函数必须付出的代价(增加或减少Reduced Cost的值) - Slack or Surplus
表示接近等于的程度
在约束条件中是<=,叫做松弛变量
在约束条件中是>=,叫做过剩变量
在约束条件中是=,值为0,该约束为一个紧约束(或有效约束)
如果一个约束条件错误,作为一个不可行约束,Slack or Surplus为负数
Slack or Surplus表示的是:约束离相等还差多少 - Dual Price
给出对偶价格的值
表示每增一个单位(约束右边的常数),目标值改变的数量(在最大化问题中目标函数是增加的,反之是减小的)
例如在本例中,c约束条件的Dual Price为1,表示2x1+x2<=600增加一个单位到2x1+x2<=601使目标值增加到-1(目标函数的Dual Price为-1),则Objective value就变为799 - 对偶价格也叫影子价格,这是由于他们表示可以用多大的价格去购买单位资源
直译
!使用sets和endsets设置集
sets:
student/stu1..stu100/: name, age;
endsets
!运行结果
Variable Value
NAME( STU1) 0.000000
NAME( STU2) 0.000000
NAME( STU3) 0.000000
NAME( STU4) 0.000000
NAME( STU5) 0.000000
NAME( STU6) 0.000000
NAME( STU7) 0.000000
NAME( STU8) 0.000000
NAME( STU9) 0.000000
NAME( STU10) 0.000000
NAME( STU11) 0.000000
…… ……
!设置集的集
sets:
! 原始集;
worker:/worker1..worker3/: efficiency; ! 工人效率;
machine:/machine1..machine3/: quality; ! 机器质量;
product:/product1..product3/: value, cost; ! 产品价值和消耗;
! 派生集;
allowed_plan(worker, machine, product): evaluation; ! 对可行方案的评价;
endsets
!设置完集后通过data和enddata赋值
data:
efficiency = 4 3 2
quality = 3 2 1
value = 50 20 10
enddata
!当三个集的对象个数一样时候,简化写
data:
efficiency, quality, value = 4 3 50
3 2 20
2 1 10;
enddata
特殊输入处理方式
将所有对象属性变量初始设置为一个值。eg:efficiency = 3;
某个对象的值为非定值,用?替代。eg:efficiency = 2 ? 4; 运算时实时输入处理
某个对象的值设为未知值,用,替代。eg:efficiency = 2, , ; 后两个work的efficiency都是未知
| 运算符名称 | 运算符涵义 |
|---|---|
| #not# | 一元运算符,否定该操作数的逻辑值 |
| #eq# | 若两个运算数相等,则为 true ,否则为 false |
| #gt# | 若左边的运算符严格大于右边的运算符,则为 true ,否则为 false |
| #ge# | 若左边的运算符大于或等于右边的运算符,则为 true ,否则为 false |
| #lt# | 若左边的运算符严格小于右边的运算符,则为 true ,否则为 false |
| #le# | 若左边的运算符小于或等于右边的运算符,则为true,否则为false |
| #and# | 仅当两个参数都为true时,结果为true,否则为false |
| #or# | 仅当两个参数都为false时,结果为false,否则为true |
eg1:多目标规划使用Lingo求解
eg2:求解两个方程组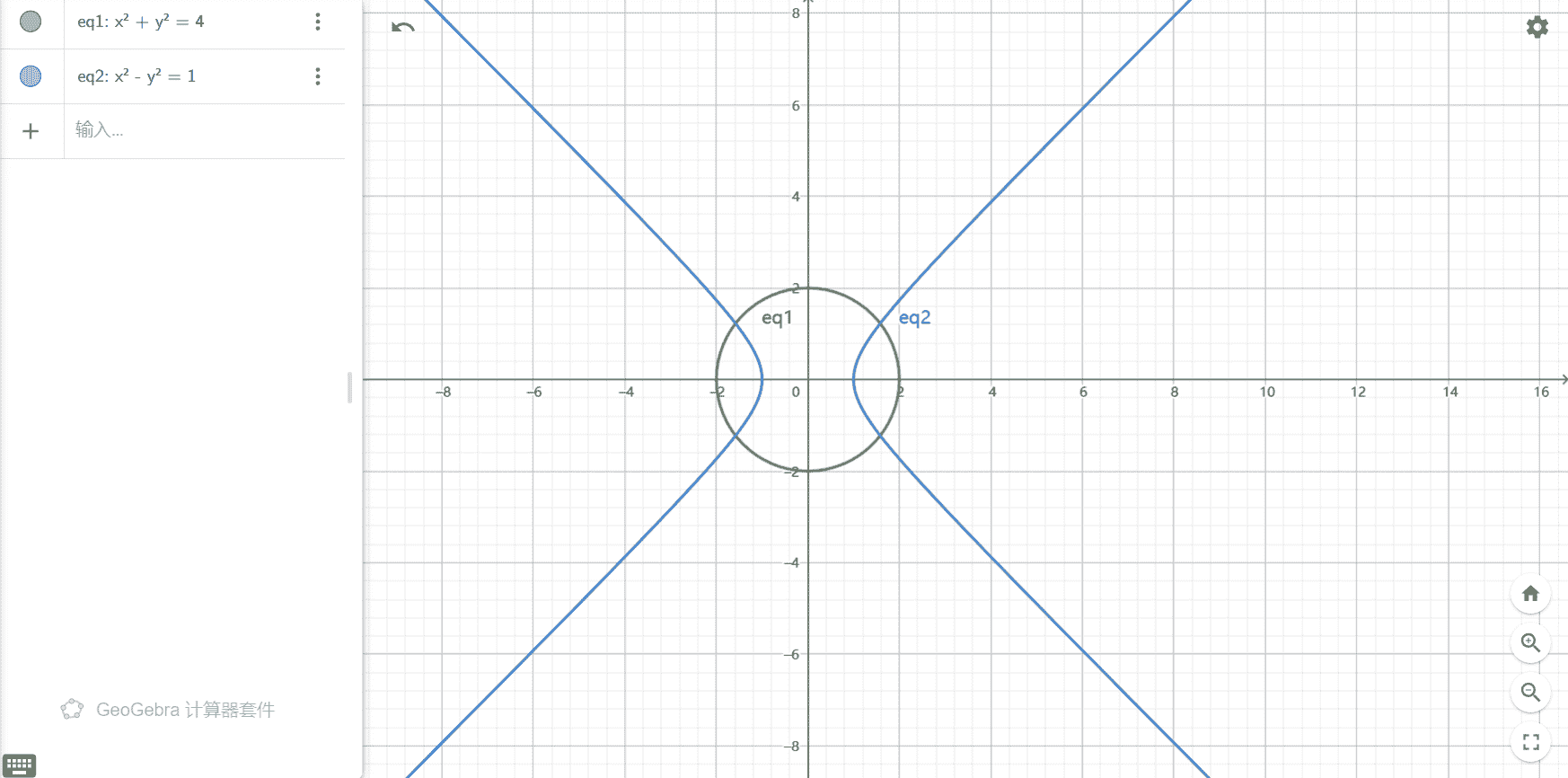
model:
submodel equation:
x^2+y^2=4;
x^2-y^2=1;
endsubmodel
submodel con1:
@free(x);x<0;
endsubmodel
submodel con2:
@free(y);y<0;
endsubmodel
calc:
@solve(equation);
@solve(equation,con1);
@solve(equation,con2);
@solve(equation,con1,con2);
endcalc
end
三、7.7日 微分方程
1.定义模型
eg1:
eg2:

曲线弧长公式
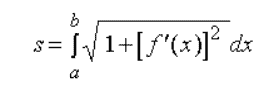
对于复合函数求导(?)

二阶常微分降阶法,换元
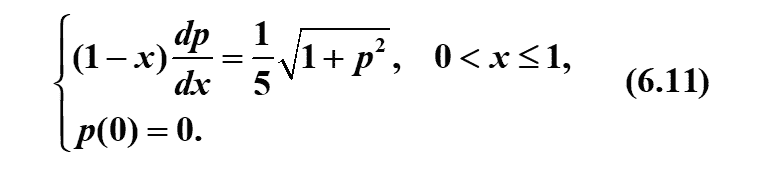
如何化简得(?)
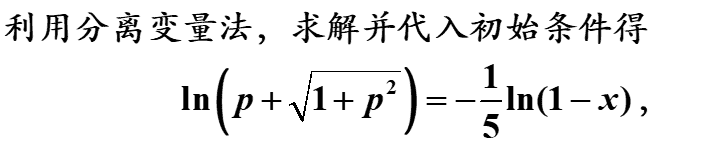
2.Matlab求解

clc清空命令行窗口
clear清空工作区变量
syms y(x)定义y(x),表示y是x的函数

diff(y)表示一阶导
diff(y,2)表示二阶导

多阶求导,且使用换元


求矩阵微分方程


ones(x,y)产生x行y列的全为1的矩阵
[s1,s2,s3]分别矩阵的第一行第二行第三行,可用此表示整个矩阵
这个是什么矩阵(?)
求解边界解

一阶微分线性方程组知识补充:一阶线性微分方程的通解 - 知乎 (zhihu.com)
(?)PPT39页开始-PPT86页结束

【Matlab 控制】微分方程 ode45() 求解并绘制曲线_matlab画微分方程组曲线_Zhao-Jichao的博客-CSDN博客
3.传染病预测模型
指数型模型:一传十,十传百

4.种群作用模型
四、7.8日 动态规划
动态规划是现代企业管理中的一种重要决策方法,可用于解决最优路径、资源分配、生产计划与库存、投资、装载、排序等问题,还可用于生产过程的最优控制等。由于它有独特的解题思路,因而在处理某些优化问题时,比线性规划或非线性规划方法更有效。
1.利用Lingo解最短路线的动态规划
model: Title Dynamic Programming;
sets: vertex/A,B1,B2,C1,C2,C3,C4,D1,D2,D3,E1,E2,E3,F1,F2,G/:L;
road(vertex,vertex)/A B1,A B2,B1 C1,B1 C2,B1 c3,B2 C2,B2 C3,B2 C4,
C1 D1,C1 D2,C2 D1,C2 D2,C3 D2,C3 D3,
C4 D2,C4 D3, D1 E1,D1 E2,D2 E2,D2 E3,
D3 E2,D3 E3, E1 F1,E1 F2,E2 F1,E2 F2,
E3 F1,E3 F2,F1 G,F2 G/:D;
endsets
data:
D=5 3 1 3 6 8 7 6
6 8 3 5 3 3 8 4
2 2 1 2 3 3
3 5 5 2 6 6 4 3;
L=0,,,,,,,,,,,,,,,;
enddata
@for(vertex(i)|i#GT#1:L(i)=@min(road(j,i):L(j)+D(j,i)));
end
这段 Lingo 代码是一个动态规划问题的模型。让我们逐行进行分析:
- 第一行指定了模型的名称为 “Title Dynamic Programming”。
- 第二行使用
sets关键字定义了一些集合,包括顶点集合(vertex)和道路集合(road),每个集合都有对应的元素。顶点集合包括 A, B1, B2, C1, C2, C3, C4, D1, D2, D3, E1, E2, E3, F1, F2 和 G;道路集合包括 A 到 B1, A 到 B2, B1 到 C1, B1 到 C2, B1 到 C3, B2 到 C2, B2 到 C3, B2 到 C4, C1 到 D1, C1 到 D2, C2 到 D1, C2 到 D2, C3 到 D2, C3 到 D3, C4 到 D2, C4 到 D3, D1 到 E1, D1 到 E2, D2 到 E2, D2 到 E3, D3 到 E2, D3 到 E3, E1 到 F1, E1 到 F2, E2 到 F1, E2 到 F2, E3 到 F1, E3 到 F2, F1 到 G 和 F2 到 G。 - 第五行使用
data关键字定义了数据。其中 D 矩阵表示从一个顶点到另一个顶点的距离,L 矩阵初始化为全零。 - 第八行使用
@for关键字开始一个循环,在每个顶点 i 上进行迭代。循环的目标是计算每个顶点 i 到其他顶点的最短路径。 - 在循环中的第九行,
L(i)=@min(road(j,i):L(j)+D(j,i))是动态规划的关键部分。它表示对于当前的顶点 i,找到能够到达顶点 i 的所有道路 j,并计算 L(j) + D(j, i) 的最小值,并将结果赋值给 L(i)。 - 最后一行表示循环结束。
总体来说,这段 Lingo 代码使用动态规划方法计算了给定图中每个顶点到其他顶点的最短路径,并将结果存储在 L 矩阵中。

2.动态规划解决利润问题
Q:某公司拟将某种设备5台分配给甲、乙、丙3个工厂,各工厂利润与设备数量之间的关系如下表所示,问这5台设备如何分配使3个工厂的总利润为最大?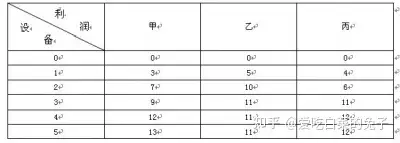
套入函数

A:仨工厂即将问题分为仨阶段,k=1,2,3。给第k个工厂分配前拥有的设备台数,s1=5。
之后看懵了…
(?)
五、7.9日建模比赛简介

省一和省二差距很小,一定注意排版,另有些老师只认MATLAB做出的数学公式。
六、7.10日 灰色预测模型
灰色系统理论是1982年由邓聚龙创立的一门边缘性学科(interdisciplinary)灰色系统用颜芭深浅反映信息量的多少。说一个系统是黑色的,就是说这个系统是黑洞洞的,信息量太少;说一个系统是白色的,就是说这个系统是清楚的信息量充足。这种处于黑白之间的系统,或说信息不完全的系统,称为灰色系统或简称灰系统。
1.灰色关联度
计算灰色关联度:
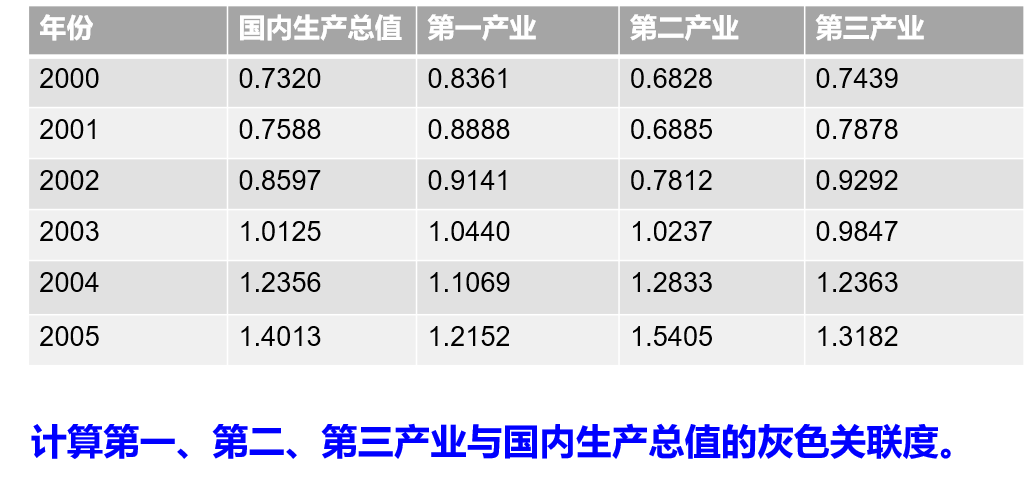
shengchanzongzhi=[0.732,0.7588,0.8597,1.0125,1.2356,1.4013];
diyichanye=[0.8361,0.8888,0.9141,1.044,1.1069,1.2152];
dierchanye=[0.6828,0.6885,0.7812,1.0237,1.2833,1.5405];
disnachanye=[0.7439,0.7878,0.9292,0.9847,1.2363,1.3182];
x0=shengchanzongzhi;
x1=diyichanye;
x2=dierchanye;
x3=disnachanye;
plot(x0, 'b*-')
hold on
plot(x1, 'g*-')
hold on
plot(x2, 'g*-')
hold on
plot(x3, 'r*-')
title('相关曲线图')
legend('总产值','第一产业', '第二产业', '第三产业')
% show
global_min = min(min(abs([x1; x2; x3] - repmat(x0, [3, 1]))));
global_max = max(max(abs([x1; x2; x3] - repmat(x0, [3, 1]))));
rho = 0.5;
zeta_1 = (global_min + rho * global_max) ./ (abs(x0 - x1) + rho * global_max);
zeta_2 = (global_min + rho * global_max) ./ (abs(x0 - x2) + rho * global_max);
zeta_3 = (global_min + rho * global_max) ./ (abs(x0 - x3) + rho * global_max);
%点除 如果a、b是矩阵,a./b就是a、b中对应的每个元素相除
r1=mean(zeta_1);
r2=mean(zeta_2);
r3=mean(zeta_3);
% r越大,关联度越大
2.灰色预测模型
所谓灰色预测模型,就是对既含有已知信息又含有不确定信息的系统进行预测,就是对在一定范围内变化的、与时间有关的灰色过程进行预测。
适用情况:

GM(1,1):Grey Model灰色模型 (1,1)只含有一个变量的一阶微分方程模型
步骤:
- 根据原始的离散非负数据列,通过累加等方式削弱随机性、获得有规律的离散数据列
- 建立相应的微分方程模型得到离散点处的解
- 再通过累减求得的原始数据的估计值,从而对原始数据预测
eg:长江水质污染预测
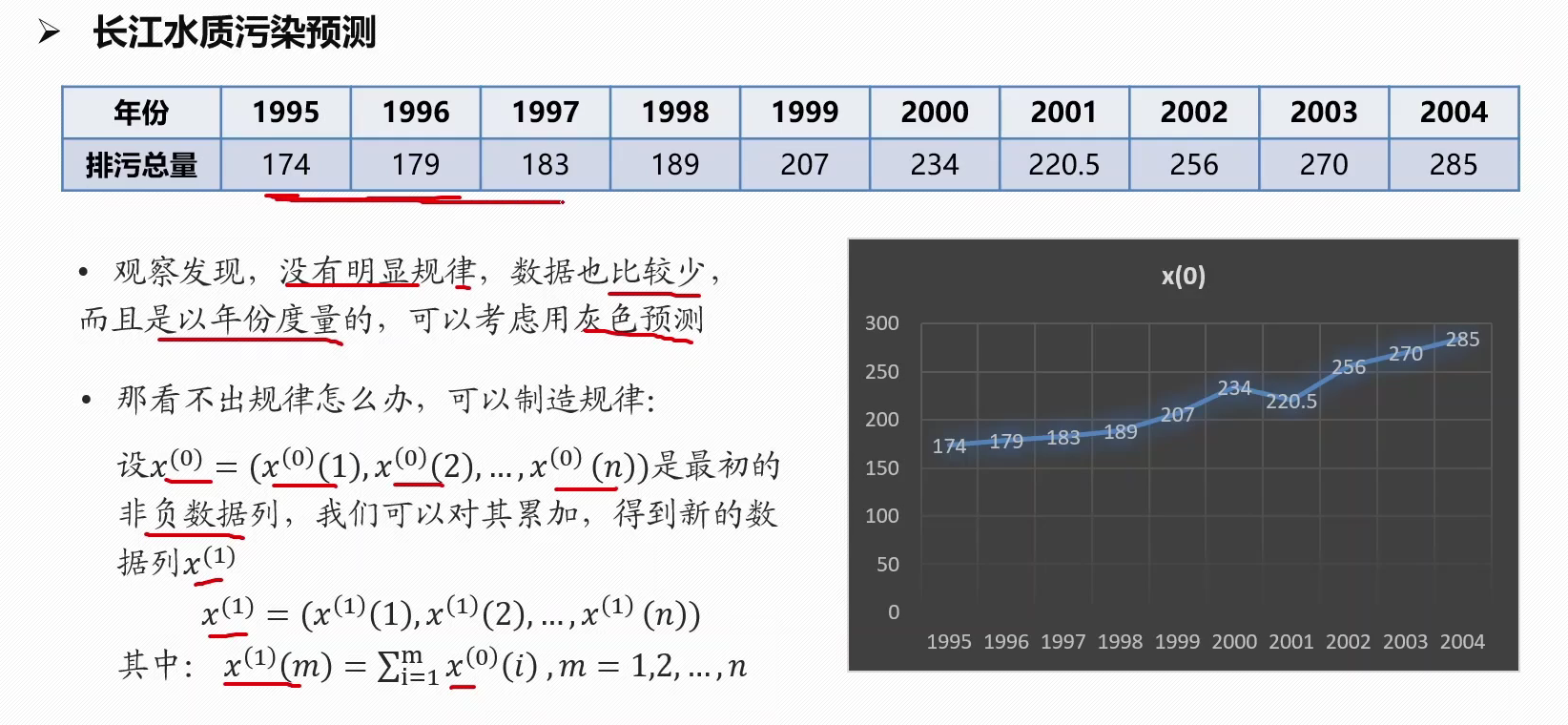
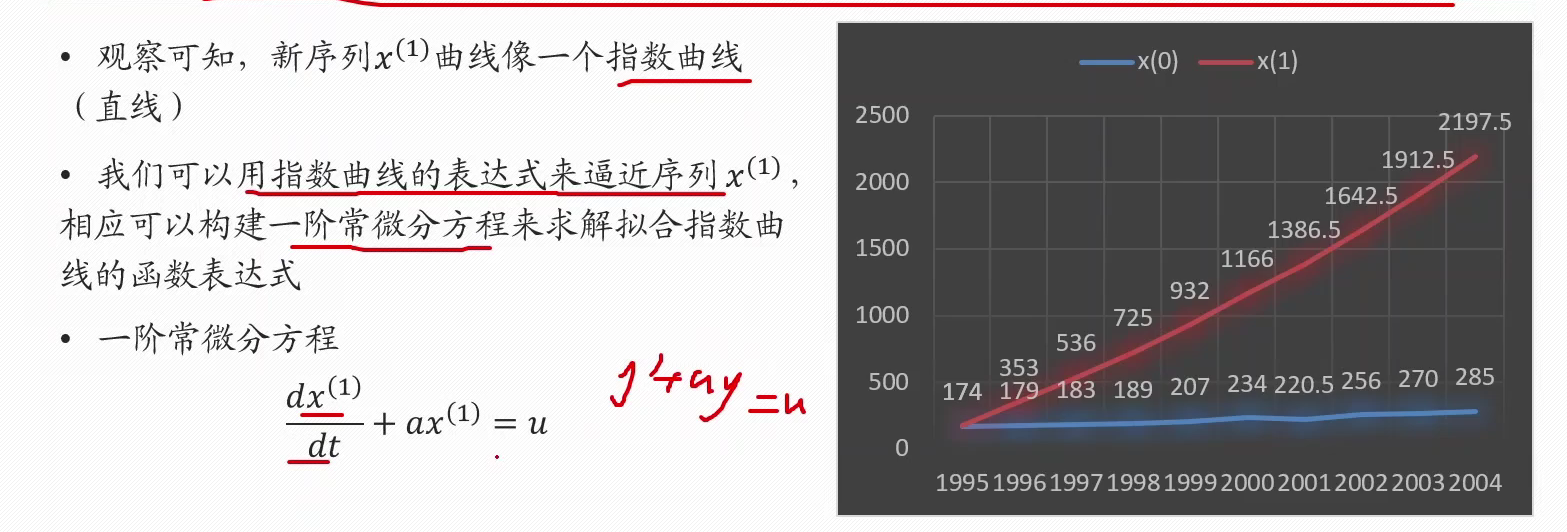
规律不明显的可以制造规律,得到累加数列S(n)观察
构建一节常微分方程

七、7.11 Matlab使用
A = [2,1;1,1]; % 不等式约束的系数矩阵 A
b = [10;8]; % 不等式约束的右侧向量 b
Aeq = []; % 等式约束的系数矩阵 Aeq
beq = []; % 等式约束的右侧向量 beq
lb = [0,0]; % 变量的下界向量 lb
ub = [inf,7]; % 变量的上界向量 ub
f = [-4,-3]; % 目标函数的系数向量 f
[x, fval, exitflag] = linprog(f, A, b);
% 使用 linprog 函数求解线性规划问题
% 输出结果包括最优解向量 x、最优值 fval 和求解器的退出状态 exitflag
这段代码描述了一个如何使用Matlab线性规划问题,并使用 linprog 函数求解。让我们逐行解释每一步:
A = [2,1;1,1];:不等式约束的系数矩阵 A,它表示两个不等式约束。在这个例子中,A是一个 2x2 的矩阵,第一行表示约束2x1 + x2 ≤ 10,第二行表示约束x1 + x2 ≤ 8。b = [10;8];:不等式约束的右侧向量 b,包含了两个不等式约束的常数。在这个例子中,b是一个 2x1 的列向量,第一个元素是 10,第二个元素是 8,分别对应着两个不等式约束的右侧常数。Aeq = [];:等式约束的系数矩阵 Aeq。在这个例子中,没有等式约束,因此 Aeq 是一个空矩阵。beq = [];:等式约束的右侧向量 beq。在这个例子中,没有等式约束,因此 beq 是一个空矩阵。lb = [0,0];:变量的下界向量 lb。在这个例子中,lb 是一个 1x2 的行向量,表示变量 x1 和 x2 的下界。这里的下界分别为 0,表示两个变量必须大于等于 0。ub = [inf,7];:变量的上界向量 ub。在这个例子中,ub 是一个 1x2 的行向量,表示变量 x1 和 x2 的上界。这里的上界分别为无穷大和 7,表示 x1 没有上界限制,而 x2 的上界为 7。f = [-4,-3];:目标函数的系数向量 f。这个向量指定了目标函数的各个变量的系数。在这个例子中,目标函数为-4x1 - 3x2。[x, fval, exitflag] = linprog(f, A, b);:使用 linprog 函数来求解线性规划问题。该函数的输出结果包括最优解向量 x、最优值 fval 和求解器的退出状态 exitflag。
以后直接让gpt来干哈哈哈
八、7.12 Lingo和数学公式格式
练习1

设 x1 为每天甲类设备上加工的 A1 的数量(kg)
设 x2 为每天乙类设备上加工的 A2 的数量(kg)
设 x3 为每天深加工设备上加工的 A1 转化为 B1 的数量(kg)
设 x4 为每天深加工设备上加工的 A2 转化为 B2 的数量(kg)
如果x3'是A1中转换B1时消耗A1的量,x4'是A2中转换成B2时候消耗B2的量,那
//使用lingo求解
SETS:
PRODUCTS / A1, A2, B1, B2 /;
DATA:
MAX_SUPPLY = 50;
MAX_LABOR = 480;
MAX_A1_PROCESSING = 100;
PROFIT(PRODUCTS) = [12, 8, 22, 16];
PROCESSING_TIME(PRODUCTS) = [12, 8, 2, 2];
PROCESSING_COST(PRODUCTS) = [0, 0, 1.5, 1.5];
YIELD(PRODUCTS) = [0, 0, 0.8, 0.75];
VARIABLES:
Supply(PRODUCTS) >= 0;
Labor >= 0;
EQUATIONS:
Obj;
MilkSupply;
LaborHours;
A1Processing;
Sales(PRODUCTS);
Obj: MAX = SUM(PRODUCTS, PROFIT(PRODUCTS) * Sales(PRODUCTS));
MilkSupply: SUM(PRODUCTS, PROCESSING_TIME(PRODUCTS) * Supply(PRODUCTS)) <= MAX_SUPPLY;
LaborHours: Labor <= MAX_LABOR;
A1Processing: Supply("A1") <= MAX_A1_PROCESSING;
Sales(PRODUCTS): Supply(PRODUCTS) = SUM(p$(PRODUCTS), YIELD(PRODUCTS) * Supply(p) - PROCESSING_COST(PRODUCTS) * Supply(p));
练习2

使用文献 五篇论文与文献
九、7.13最小二乘曲线拟合
曲线拟合——最小二乘法( Ordinary Least Square,OLS)_最小二乘法求拟合曲线_阿慧吖的博客-CSDN博客
十、7.14图与网络分析
离散数学相关
最短路径:
- 单源最短路径:DFS
- 多源最短路径:FLoyed 可以解决负边权问题
- 赋权无向图最短路径:二叉树的遍历
最短路径算法-[最短路径问题]—Dijkstra 算法最详解 - 知乎 (zhihu.com)
(27条消息) 图论算法之最短路径(Dijkstra、Floyd、Bellman-ford和SPFA)_图论最短路径算法_HX_2022的博客-CSDN博客
十一、7.15
十二、7.16 模糊数学
模糊数学笔记:一、模糊集及其运算性质 - 知乎 (zhihu.com)
模糊集 隶属度 分解定理 模糊度







十三、7.17 数据处理与分析

十四、7.19 建模总览
组队分工

进度:第一天完成第一题,第二天完成剩下题,第三天论文排版